One of the main questions that my team ask potential candidates during technical interviews, is the Producer – Consumer Problem. We have found over the years that this problem is one of the main issues we have with potential new hires. Many a programmer has been tripped up by this problem, and the related questions that follow.
The concept is simple, we have one of more threads that are “Producers” of something, usually data (Events, Structures or Objects are data) in the case of computers and programming.
“Consumers” are other threads that receive and use the data produced by the “Producers”.
Many different threading concepts are used when creating a Producer-Consumer scenario and it is a great real-world mechanism that we use to solve multi-threaded problems on a day to day basis; and therefore it is an extremely useful to test potential new hires.
For illustration in this blog post, I have created three separate Java classes, which are below. First is the “Test Driver”, this is the main program used the test and potentially debug the Producer and Consumer threads. The second is the Producer. This of course is the Producer thread implementation. And finally the Consumer, which like it’s counterpart the Producer is the Consumer thread implementation.
In my example code below, the Producer and Consumer will run forever (until the user sends the interrupt signal ie. Cltr-C or otherwises kills the process). The Producer will create 10 random Long objects every time is obtains the lock on the “listLock” object monitor, and will than wait while the “sharedList” ArrayList object is NOT empty. The Producer will also Notify ALL other threads waiting on the listLock Object. There is an important difference between the notify() and notifyAll() methods on the java base Object. Both are used to notify waiting threads that are blocked on the same object monitor that it’s time to wake up, but the notify all will wake up ALL threads that are blocked on that object monitor, and based on the OS implementation that threads will compete for object monitor lock, before continuing execution. This is good for situations where you have multiple consumers blocked on the same Object Monitor lock and you want any of them to potentially being processing once that lock becomes available. The rest will block due to the synchronization of the critical section of code which they originally were in the waiting state for. This is of course assuming you wrote your code correctly.
Once the consumer wakes up from the waiting step and obtains the lock on the Object Monitor “listLock”, the example code I have written will consume all data within the ArrayList safely, before notifying the Producer (technically any other threads synchronized and waiting on the listLock) to wake up. In this case the Producer will wake from the waiting state, but it is still blocked because the Consumer has not yet released the lock on the listLock object. Once the Consumer’s loop enters the while sharedList isEmpty check, the Consumer will execute listLock.wait(), entering itself into the wait state, and releasing the lock on the listLock object monitor. This will now allow the Producer to finally being executing, and the process will repeat, with the Producer producing 10 random objects into the shared list. The process will run forever like this, passing data between Producer and Consumer safely, without either thread corrupting the shared memory space, in this case the sharedList ArrayList object. Please note that I did not use any Collection synchronization mechanisms, other than my own. This is perfect for the purpose of testing the Producer-Consumer problem. To use any of Java’s facilities to create thread-safe collections would be defeating the purpose of trying to demonstrate an understanding of multi-thread programming.
Test Driver:
/**
* File: PCTester.java
* Creation Date: June 24, 2013
* Author: Robert C. Ilardi
*
* Here we have a Test Driver for our Producer-Consumer example.
*
*/package com.roguelogic.tests;import java.util.ArrayList;publicclassPCTester{publicstaticvoidmain(String[]args){try{// This creates a Object Monitor or "lock"// that can be shared between threads.// Technically in Java, any Object// instance of any class// can be used as an Object Monitor.// As a matter of convenience, most// programmers,// simply use an instance of the// class Object to represent the// lock.ObjectlistLock=newObject();// This ArrayList will become our// Shared resource that both the// "consumer" threads and the// "producer" threads will// use to pass data back and// forth. On specifically in// this case, it's one// directionally from the// Producer to the Consumer.ArrayList<Object>sharedList=newArrayList<Object>();// Here we are creating the Producer// It is an object which I have extended// the Thread class from. This makes the// Producer itself a thread.Producerp=newProducer();// As you can see I'm passing the listLock object monitor.p.setListLock(listLock);// I'm also passing the Shared List ArrayList to this Producer.p.setSharedList(sharedList);// We are now going to create a Consumer Thread.// Like the Producer, it also extends from the Thread class// and I have also set it up to receive references of// both the listLock Object Monitor and the sharedList ArrayList.Consumerc=newConsumer();c.setListLock(listLock);c.setSharedList(sharedList);p.start();// We are going to start the Producer Thread.c.start();// We are going to start the Consumer Thread.// The next two lines of code// Simply ensures that the main method// waits on the producer and consumer thread// to exit before continuing.p.join();c.join();}catch(InterruptedExceptione){e.printStackTrace();}}}
/**
* File: Producer.java
* Creation Date: June 24, 2013
* Author: Robert C. Ilardi
*
* This is the Producer example thread class.
*
*/package com.roguelogic.tests;import java.security.SecureRandom;import java.util.ArrayList;publicclassProducerextendsThread{privateArrayList<Object>sharedList;privateObjectlistLock;publicProducer(){super();}publicvoidsetListLock(ObjectlistLock){this.listLock=listLock;}publicvoidsetSharedList(ArrayList<Object>sharedList){this.sharedList=sharedList;}publicvoidrun(){// We are using Secure Random, because the regular Random is boring.SecureRandomsrnd=newSecureRandom();// Here we have the synchronized block// which is on the listLock Object monitor.// This creates the critical section of code// that marks the block of code within it// that the operations are atomic.// However listLock.wait will cause the thread// to stop processing and allow other threads// to obtain the lock on the Object Monitor.synchronized(listLock){try{// Run foreverwhile(true){// Add 10 random numbers into the shared queue.for(inti=1;i<=10;i++){LongnxtLng=srnd.nextLong();sharedList.add(nxtLng);}listLock.notifyAll();// Notify ALL other threads to wake up// Wait while the Shared List had data in itwhile(!sharedList.isEmpty()){listLock.wait();}}}catch(InterruptedExceptione){e.printStackTrace();}}}}
Consumer:
/**
* File: Consumer.java
* Creation Date: June 24, 2013
* Author: Robert C. Ilardi
*
* This is the Consumer example thread class.
*
*/package com.roguelogic.tests;import java.util.ArrayList;publicclassConsumerextendsThread{privateArrayList<Object>sharedList;privateObjectlistLock;publicConsumer(){super();}publicvoidsetListLock(ObjectlistLock){this.listLock=listLock;}publicvoidsetSharedList(ArrayList<Object>sharedList){this.sharedList=sharedList;}publicvoidrun(){intslSz;Objectobj;// Just like the Producer class// the synchronized block creates// a block of atomic code also// know as the critical section// as it potentially interacts with// other threads.synchronized(listLock){try{// Loop foreverwhile(true){// Wait while the list of empty.// Technically this means we can// wake up as soon as a single// object is populated in the shared list// however since our producer implementation// does not notify until 10 items are added// to the list, we won't really wake up// until all 10 are added.while(sharedList.isEmpty()){listLock.wait();}// Note: even if the listLock.wait()// receives the notification, it doesn't// mean the code will start running,// because we are synchronized on the listLock// therefore until the lock is released by// the thread that has the lock, we will still wait.// Loop until the sharedList is empty.while(!sharedList.isEmpty()){slSz=sharedList.size();obj=sharedList.remove(0);System.out.println("Consumer("+super.getId()+")> Shared List Size = "+slSz+" ; Object = "+obj);}// When we are done make sure to notify other threads// This is extremely important if the Producer is in the waiting// state. However this thread still holds the lock// until the listLock.wait() is invoked in the next iteration// of the while loop. If we forget to notify, both threads// simply wait forever. Give it a try. Comment it out.listLock.notifyAll();}}catch(InterruptedExceptione){e.printStackTrace();}}}}
Although, technically I am giving away a partial question and definitely a topic that I have my teams’ test potential new hires on their technical interviews, I think it is important for students of computer science, and programming in general to have a solid understanding of the Producer-Consumer problem. I have found that in all complex systems, and definitely systems that are multi-tier, 3-tier or more distributed systems, a lack of understanding of the Producer-Consumer problem, severely curtails the ability of programmers to produce reliable systems. Again, I hope this post has been helpful!
Just Another Stream of Random Bits…
– Robert C. Ilardi
For the last 8 years that I have been giving my architects, tech leads, and developers their yearly performance reviews, I have been using the acronym “SFEMS”.
Arguably you can say I should just be telling my architects and maybe tech leads that they need to design and ensure their team’s implementations follow the SFEMS (Stable, Flexible, Extensible, Maintainable, Scalable) mantra.
However I feel that every person in my development groups should eat, drink, sleep, and *CODE* with SFEMS always on their minds.
Everyone in my group is required to ensure they design and write code that meets this the SFEMS Standards. I don’t care how junior a developer is, we preach it to them from their first day on the job, even if they are just one day out of school.
When I have my town halls and other group meetings, I always remind my developers that the expectation is Quality over Quantity (in terms of how much code they can write in any given day), and that refactoring their code to ensure it meets SFEMS standards is the norm.
It doesn’t matter how small or large of a component a developer or team of developers are writing, it is always important that the code is first of all STABLE – that is the code should be as close to bullet proof as possible; although I make it understood that everyone and anyone can write code that contains a bug or two. Code should be expected to be used in a one off API where the objects containing your code is used once than discarded or the same classes could be used in a Daemon process where the objects may live for hours or even days to weeks without the process being restarted. This is where unstable code usually becomes a problem because it may work by contain a memory leak or a database connection leak, or other resource utilization issue, and it is why the same code may work if it’s only used once in a while in a process and it causes weird behavior or even crashes in long running processes, or short running processes that use the same code in a loop with thousands or even millions of iterations.
Second and Third, their code needs to be Flexible and Extensible. You may say, well what’s the difference? Well to me, code can make an application be flexible if it can be helps the broader application or system which it is part of work under a range of circumstance. Think of it like a person being flexible in their abilities to handle multiple situations or to be able to come up with solutions and work-around automatically to a problem set within the same knowledge domain. In software this is when for example, I am writing a ETL (Extraction, Transformation, Loading) loader and my code should be able to contend with small variances in the data without failing the overall process. More specifically if the loader code encounters one or two records with incorrect Country Codes, the loader should be able to be configured to have a threshold of corrupt records in the source data while still completing the process if that threshold is not met and perhaps report the error records to the development team automatically via email or some other more complex method such as a error queue processing table. We can configure the threshold to be ZERO or ONE and therefore as soon as any error is encountered with fail out the process. But this is where Flexibility comes into the picture, and the threshold can be dictated to us by the business or users.
In terms of Extensibility, I expect all of my programmers to follow good OOP / OOD so that their code can be reused and extended to help us cut down on our time to market. For years I have used the approach of creating an “Internal SDK” (Software Development Kit) at the start of a project when I take over as the manager or architect. We usually create a module in our source code repository called “commons” which contains our groups SDK. It contains all the frameworks, wrappers, and useful utilities that are common across our Middleware, Batch, and Standalone processes. In the case where the User Interface is written in the same language as the rest of the system, the UI is expected to use commons as well. Over the lifetime of the systems I own and develop, we have a process of “Promoting to Commons” as objects and other code become so useful they become “common” within our system, and the code will be refactored and moved from whatever source code repository module it was originally in to the Commons module. We use this same principal for non-object oriented languages or components, such as scripts. Even though common scripting languages we use such as Perl and Python either have the capabilities to create Objects and use OOP concepts or are Object Oriented themselves, most times I find that we treat scripting languages as procedural languages, but this doesn’t mean we can’t have reuse. We enforce the same strategies we do in Java or C#. We always programming forward thinking, so if we feel a subset of functions a script that we write can be useful for future scripts, we create a library of common scripts of functions or objects. So I always tell my team ensure that whenever possible if you even just have a feeling that your code or parts of your code can be useful to someone else, ensure that it written so that it can be reused as much as possible. Or if you notice that you are going to be writing the same thing over again, stop and go back to where you wrote something similar before and refactor the code so that the original becomes reusable two both the original component and the new component, or at least extract the common functions into a base class or utility package.
Fourth, we must ensure that whatever we write is Maintainable, and that means maintainable by other developers. I am very straight forward in telling everyone that we write systems to last 20 years at least, no matter if we or others will replace it sooner, the assumption must be at least 2 decades. And therefore we cannot afford to assume the same people will be on the same project to work on the code they personally wrote or helped to write over that long of a period. Therefore we need to put ego aside for the team’s sake and write code that is clean and clear, and simply for other members of the team to read and make enhancements to. As managers, architect, and leads, we need to watch over our developers to ensure they are not writing code that only a small subset of people or only one person can maintain. If we allow this in our system, we are setting ourselves up for failure in the medium to long term. Maintainability encompasses Extensibility and the next and final word in the SFEMS mantra Scalability. For systems to be Extensible and Scalable, they MUST be easily maintainable. Otherwise, they really can’t be considered build to be forward looking and therefore are not easily extensible and possibly not scalable as well, if we can’t change the code within reasonable cost to handle changes to the business, system load, and user requested enhancements.
The Fifth and final component to the SFEMS mantra is ensuring the code and systems we develop are Scalable. Writing systems to be scalable is not an easy task. We often write code to solve a specific problem. Perhaps we have to write a middleware which will be used by a front-end that will have only 1000 users today. We can do that, because that’s the requirement and we will buy the hardware we need and architect the system to handle this user load. But how will the system perform if we add another couple of hundred users? How about a thousand more? Will it even allow that may users to be online at the same time? How do we build a system within cost that can scale in the future when we don’t even know what the upper limit will be (if there even is one)? It’s definitely not easy, and building scalable systems is an entire topic all to itself worth many volumes of books and articles. However if we followed the first 4 components of SFEMS (Stable, Flexible, Extensible, Maintainable), our systems should be able to scale if we are given the proper resources to enhance it. In my mind we should always build our systems to expect between 1.5 and 2 times the expected user or data load on the system that the original requirements state. If we can do this, we have already bought us enough time to work on ensure the system is Stable, Flexible, and Extensible to scale beyond 2 times the original load. There’s really no way to make a system handle unlimited system loads. Eventually it will come down to a physical limit of the computing platform your code is running on, so we must build systems with Scalability in mind through the first 4 components of the SFEMS mantra so that with the right investment in extending the system to handle the new system loads, we can within reasonable cost models and time to market accomplish the required enhancements.
Each of the five components of SFEMS deserve at least a separate post all to their own. However I hope this article will help everyone from junior developers all the way up to senior technology managers on their journey when building large scale enterprise class systems that are expected to write a multi-decade lifespan.
So just remember “SFEMS”! – Stable, Flexible, Extensible, Maintainable, Scalable
Just Another Stream of Random Bits…
– Robert C. Ilardi
I recently participated in a company sponsored people strategy event, where I was part of a panel of leaders at various levels within my department.
One of the questions posed to the Panel which we didn’t have an opportunity to answer was “So, if you had your own t-shirt, what would your catch phrase say?”
Unfortunately, we ran overtime and we did not have a chance to answer this question to the forum, so I figured I post my answer here and perhaps even send this link to my teams.
Being one for dramatic presentations, I actually brought in my own T-Shirt to the event, to hold up and show, that not only “would I” have a T-shirt that has my catch phrase, I actually DO have a T-Shirt with my “catch phrase” on it, and I wear it regularly. I also have a Polo Shirt with the RogueLogic logo on it!
It is a simply white T-Shirt with the RogueLogic Logo on it. RogueLogic as you might already know from reading my Blog, is own my personal web site as well as the web site for the Software Company I tried to start while in College.
Here is the actual T-Shirt:
So what does the “catch phrase” or really the moniker “RogueLogic” really mean?
Well back in 1999 when I was starting my own Software company, I was trying to come up with a name that represented the Revolutionary ideas my company was going to build products upon. I always thought of myself as someone that not only thinks out side of the box, but actually is a “Rogue” Thinker. Therefore RogueLogic was born! I also liked the fact that both my name “Robert” and “RogueLogic” starts with the same letter…
How does this apply to me today in my professional career? And why would I choose to share this at a professional company sponsored discussion panel, that was video conferenced with over 1000 viewers around the globe? Well, because thinking so differently, that it way beyond “thinking outside of the box”, to the point where it’s Mad, Ludacris, any even “Rogue” is exactly how I achieve so much in my professional career in such a short time, and it is what I rely on to get me through the toughest software engineering problems my team and I face on a daily basis. It’s what separates us from the rest of the Wall Street Software Development Pack.
This is actually a blog entry I posted on RogueLogic.com back in 2009:
With the 10th anniversary of RogueLogic coming up, I thought it would be nice to quickly go over the evolution of the RogueLogic logos since the birth of my moniker in 1999:
1. The original RogueLogic Logo created back in 1999 when I founded the company…
2. This is the second version of the logo. I used this version, when I briefly changed the background color of the website from white to black.
3. This is the current version of the RogueLogic Logo. I originally created this version back in 2001, when I was taking a Web Design Class.
Just Another Stream of Random Bits…
– Robert C. Ilardi
Back in 1997, US Robotics had a small banner advertisement on AOL for their 56K X2 modem, which I happened to own at the time, so I took a screen capture and cropped out just the logo. After many searches using Google Image Search, I have yet to find anyone else to has a copy of this Image. Please let it be known that I do not own the Image below nor to I claim any ownership or any other rights to it. Instead I have posted it here for Internet Posterity.
Original US Robotics “They Use X2”
Check out US Robotics which as of 2013 still produces 56K modems!
Base on the implication which this image tries to portray, at least my interpretation, that Advanced Alien Civilizations use “X2” 56K technology, I created in Parody (Fair Use in Copyright Terms) my own version which Implies “Advanced Alien Civilizations use RogueLogic Technology!”, which I have done for use as my Personal Instant Messaging Buddy Icons:
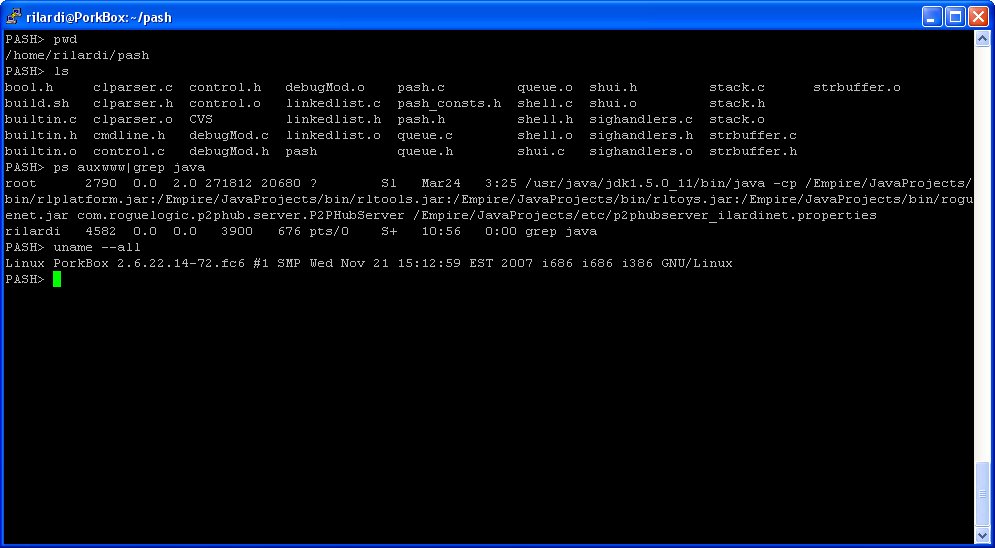
Back in late 2004, I decided to finally write my own Unix SHell from scratch in the C Programming Language. One of the professors that taught Operating Systems at Polytechnic University back when I was an undergrad, actually made his class write their own SHells as one of the projects for the course. Unfortunately, he stopped teach that course when it was my turn to take Operation Systems, so I never got to build one while I was in school.
So, one day while I was working at Lehman Brothers, I decided it was time I finally wrote my own. I was more than 3 years out of college at that time, and working full time, I gave up working on my own commercial projects to focus on some fun development like implementing my own Huffman Compression and Decompression utilities, as well as the PASH SHell.
So what does PASH stand for? – It’s named after my wife: Paula Anglo SHell. Yes, I know, very romantic…
Purpose?
Just to learn how a Unix SHell works. I wanted to handle multiple pipes correctly, redirects, etc. It’s not a complete shell, but it works ok for the purpose of learning and experimenting with low level Unix system calls. By writing this shell, I learned all about fork(), exec(), dup2(), pipe() / pipeline, and other Unix system calls, and more importantly, how to use them correctly to create a SHell process that can sit on top of a Unix Operating System and allow the user to execute commands.
Just for your viewing (and searching) pleasure, I concatenated all the separate source files into a single Text File. Enjoy!
Some other nice things about this code, is that I tried to make it as self contained as possible, therefore it includes my own Linked List, Stack, Queue, String Buffer implementations in C. So I expect that this code will be useful for students of the C language in general, not just for students of Operating Systems or Unix SHells…
I would like to hear back from professors, students, and in general anyone else who is a programmer or interested in programming on this SHell Implementation. I know it’s not complete, it lacks support for it’s own Shell Scripting language, etc, but it does support multiple pipes, redirects, etc, and it a very good educational tool, at least in my opinion. Please feel free to contact me or leave me comments on this post!
//=================================================================>
//pash.c/*
Author: Robert C. Ilardi
Date: 11/5/2004
Description: The Paula Anglo SHell (PASH) Main Driver Program Implementation
*/#include "pash.h"intmain(intargc, char*argv[], char*envp[]){intexitCode=1;
//SetDebugModetoONfordevelopmentpashSetDebugMode(false);
//InstallSignalHandlersinstallSignalHandlers();
//SetPrompt? Notfornow, justacommentplaceholder
//InstallUserInterfaceFunctionsinControlLoopinstallUserInterfaceGet(getCmdLine);installUserInterfacePrompter(printPrompt);
//StartProcessingUserInputuntilUserExitsexitCode=runShell();returnexitCode;}
//=================================================================>
//pash.h/*
Author: Robert C. Ilardi
Date: 11/5/2004
Description: PASH Shell Main Driver Program Header
*/#ifndef PASH_H#define PASH_H#include <sys/types.h>#include <unistd.h>#include <stdlib.h>#include <stdio.h>#include "debugMod.h"#include "shui.h"#include "sighandlers.h"#endif
//=================================================================>
//pash_consts.h/*
Author: Robert C. Ilardi
Date: 11/15/2004
Description: Contains some Pash Constants
*/#ifndef PASH_CONSTS_H#define PASH_CONSTS_Hstaticconstchar*PASH_VERSION="0.9";staticconstchar*PASH_TITLE="The Paula Anglo SHell (PASH)";staticconstchar*PASH_AUTHOR="Robert C. Ilardi";staticconstchar*PASH_COPYRIGHT_DATE="2004";staticconstchar*PASH_COPYRIGHT_HOLDER="Robert C. Ilardi";staticconstchar*PASH_URL="http://roguelogic.com:3979/";#endif
//=================================================================>
//shell.c/*
Author: Robert C. Ilardi
Date: 11/15/2004
Description: PASH Unix Shell Implementation
*/#include "shell.h"constintINTERNAL_CMD_SUCCESS=0;constintINTERNAL_CMD_FAILURE=1;constintINTERNAL_CMD_UNKNOWN=2;staticvoiddebugCmdStack(structStack*);staticvoiddebugCmdLine(structCmdLine*);staticchar**paramListToArray(structCmdLine*);staticvoiddoRedirects(structCmdLine*);staticboolcreateNeededPipe(structCmdLine*);staticvoiddoPipes(structCmdLine*);staticvoidshellWaitAll();staticvoidcloseParentPipes();staticvoidupdatePipeIndexes(structCmdLine*);staticvoidclearCmdStack(structStack*);bool_shellNoExec=false;int*pipePairs;pid_t*pidList;intprocIndex;intpidCnt;intpipeIndex;intnextOut;intnextIn;intprevOut;intprevIn;intfutureOut;voidexecuteCmdStack(structStack*cmdStack){structCmdLine*cmdLine;boolexecOk;structListNode*param;prevIn=nextIn=0;futureOut=prevOut=nextOut=1;procIndex=0;pipeIndex=0;pidList=NULL;pipePairs=NULL;pidCnt=stackSize(cmdStack);if(pidCnt>0){pidList=(pid_t*)malloc(sizeof(pid_t)*pidCnt);pipePairs=(int*)malloc(sizeof(int)*pidCnt*2);while(!stackIsEmpty(cmdStack)){cmdLine=(structCmdLine*)stackPop(cmdStack);execOk=executeCmd(cmdLine);if(!execOk){fprintf(stderr, "Command Execution Aborted!\n");stackPush(cmdStack, cmdLine); //SoclearCmdStacktakescareofeverythingbreak;}}clearCmdStack(cmdStack);closeParentPipes();if(execOk){shellWaitAll();}if(pipePairs!=NULL){free(pipePairs);}if(pidList!=NULL){free(pidList);}}}staticvoidclearCmdStack(structStack*cmdStack){structCmdLine*cmdLine;while(!stackIsEmpty(cmdStack)){cmdLine=(structCmdLine*)stackPop(cmdStack);listDestroy(cmdLine->parameters, true);free(cmdLine->inFile);free(cmdLine->outFile);free(cmdLine->errFile);free(cmdLine);}}char**paramListToArray(structCmdLine*cmdLine){char**paramArr=NULL;structListNode*cur;intcnt, len;structLinkedList*params=cmdLine->parameters;len=listSize(params);if(len>0){paramArr=(char**)malloc(sizeof(char*)*(len+2));paramArr[0]=cmdLine->command; //ByConventionparamArr[len]=NULL; //NULLTerminatorcnt=1;cur=params->head;while(cur!=NULL){paramArr[cnt++]=(char*)cur->item;cur=cur->next;}}returnparamArr;}staticvoidshellWaitAll(){inti, status, chdStatus;for(i=procIndex-1;i>=0;i--){if(waitpid(pidList[i], &status, 0)<0){fprintf(stderr, "waitpid() failed\n");break;}elseif(WIFEXITED(status)){chdStatus=WEXITSTATUS(status);
//printf("Child Process (PID=%d) has exited with Status=%d.\n", pidList[i], chdStatus);}}}staticvoidcloseParentPipes(){inti;for(i=0;i<pipeIndex;i++){if(pipePairs[i]!=-1){close(pipePairs[i]);}}}boolexecuteCmd(structCmdLine*cmdLine){pid_tpid;intstatus;boolretVal;
//DebugCmdLineObjectif(pashDebugMode()){debugCmdLine(cmdLine);}if(checkBuiltIn(cmdLine)==INTERNAL_CMD_UNKNOWN&&!_shellNoExec){
//ExecuteExternalProgramasChildProcessretVal=createNeededPipe(cmdLine); //CreatePipeasneededif(retVal){pid=fork(); //ForkChildif(pid){
//ParentpidList[procIndex]=pid;procIndex++;updatePipeIndexes(cmdLine);retVal=true;}elseif(pid==-1){fprintf(stderr, "Child fork() failed!");retVal=false;}else{
//Child
//printf("Executing Child Process: %s\n", cmdLine->command);doRedirects(cmdLine);doPipes(cmdLine);execvp(cmdLine->command, paramListToArray(cmdLine));perror(NULL);fprintf(stderr, "Child Process (CMD='%s') Execution Failed!\n", cmdLine->command);_exit(1);}}}else{retVal=true;}listDestroy(cmdLine->parameters, true);free(cmdLine->inFile);free(cmdLine->outFile);free(cmdLine->errFile);free(cmdLine);returnretVal;}intcheckBuiltIn(structCmdLine*cmdLine){intstatus;if(builtInSupport(cmdLine)){status=(builtInExecute(cmdLine) ? INTERNAL_CMD_SUCCESS:INTERNAL_CMD_FAILURE);}else{status=INTERNAL_CMD_UNKNOWN;}returnstatus;}staticvoiddoRedirects(structCmdLine*cmdLine){FILE*myStdIn, *myStdOut, *myStdErr;if(cmdLine->inFile!=NULL){myStdIn=fopen(cmdLine->inFile, "r");if(dup2(fileno(myStdIn), fileno(stdin))<0){perror(NULL);_exit(1);}}if(cmdLine->outFile!=NULL){myStdOut=fopen(cmdLine->outFile, (cmdLine->appendOut ? "a":"w"));if(dup2(fileno(myStdOut), fileno(stdout))<0){perror(NULL);_exit(1);}}if(cmdLine->errFile!=NULL){myStdErr=fopen(cmdLine->errFile, "w");if(dup2(fileno(myStdErr), fileno(stderr))<0){perror(NULL);_exit(1);}}}staticboolcreateNeededPipe(structCmdLine*cmdLine){intpipePair[2];boolretVal;pipePairs[pipeIndex]=-1;pipePairs[pipeIndex+1]=-1;if(cmdLine->pipedIn){if(pipe(pipePair)!=0){fprintf(stderr, "Could NOT create PIPE!\n");perror(NULL);retVal=false;}else{pipePairs[pipeIndex]=pipePair[0];pipePairs[++pipeIndex]=pipePair[1];pipeIndex++;retVal=true;}}else{retVal=true;}returnretVal;}staticvoidupdatePipeIndexes(structCmdLine*cmdLine){if(cmdLine->pipedIn){prevIn=nextIn;nextIn+=2;prevOut=futureOut;futureOut+=2;}if(cmdLine->pipeOut){nextOut+=2;}}staticvoiddoPipes(structCmdLine*cmdLine){if(cmdLine->pipedIn&&!cmdLine->pipeOut){
//SinglePipeInif(pashDebugMode()){printf("%s is using pfd(nextIn = %d): %d\n", cmdLine->command, nextIn, pipePairs[nextIn]);}if(dup2(pipePairs[nextIn], fileno(stdin))<0){fprintf(stderr, "Could NOT dup2 pipe on stdin!\n");perror(NULL);_exit(1);}close(pipePairs[nextOut]);}elseif(cmdLine->pipedIn&&cmdLine->pipeOut){
//PipeInandPipeOutif(pashDebugMode()){printf("%s is using pfd(nextIn = %d): %d\n", cmdLine->command, nextIn, pipePairs[nextIn]);}if(dup2(pipePairs[nextIn], fileno(stdin))<0){fprintf(stderr, "Could NOT dup2 pipe on stdin!\n");perror(NULL);_exit(1);}close(pipePairs[futureOut]);if(pashDebugMode()){printf("%s is using pfd(prevOut = %d): %d\n", cmdLine->command, prevOut, pipePairs[prevOut]);}if(dup2(pipePairs[prevOut], fileno(stdout))<0){fprintf(stderr, "Could NOT dup2 pipe on stdout!\n");perror(NULL);_exit(1);}close(pipePairs[prevIn]);}elseif(cmdLine->pipeOut){
//SinglePipeOutif(pashDebugMode()){printf("%s is using pfd(nextOut = %d): %d\n", cmdLine->command, nextOut, pipePairs[nextOut]);}if(dup2(pipePairs[nextOut], fileno(stdout))<0){fprintf(stderr, "Could NOT dup2 pipe on stdout!\n");perror(NULL);_exit(1);}close(pipePairs[nextIn]);}}staticvoiddebugCmdLine(structCmdLine*cmdLine){structListNode*param;printf("Command: %s\n", cmdLine->command);printf("Parameters: ");param=cmdLine->parameters->head;while(param!=NULL){printf("'%s' ", (char*)param->item);param=param->next;}printf("\n");printf("OutFile(%s): %s\n",
(cmdLine->appendOut ? "Append":"Overwrite"),
cmdLine->outFile);printf("InFile: %s\n", cmdLine->inFile);printf("ErrFile: %s\n", cmdLine->errFile);printf("Piped In: %s\n", (cmdLine->pipedIn ? "YES":"NO"));printf("Pipe Out: %s\n", (cmdLine->pipeOut ? "YES":"NO"));printf("Background Process: %s\n", (cmdLine->backgroundProcess ? "YES":"NO"));}voidsetShellNoExec(boolnoExec){_shellNoExec=noExec;}
//=================================================================>
//shell.h/*
Author: Robert C. Ilardi
Date: 11/15/2004
Description: PASH Unix Shell Header
*/#ifndef PASH_SHELL_H#define PASH_SHELL_H#include "linkedlist.h"#include "stack.h"#include "cmdline.h"#include "bool.h"#include "builtin.h"#include "debugMod.h"#include <stdlib.h>#include <stdio.h>#include <sys/types.h>#include <unistd.h>#include <sys/wait.h>#include <errno.h>voidexecuteCmdStack(structStack*);intexecuteCmd(structCmdLine*);voidsetShellNoExec(bool);#endif
//=================================================================>
//shui.c/*
Author: Robert C. Ilardi
Date: 11/7/2004
Description: Shell Command Line User Interface Implementation
*/#include "shui.h"char*_prompt;voidsetPrompt(char*prompt){_prompt=prompt;}char*getCmdLine(){char*cmdLine=(char*)malloc(CMD_LINE_LEN);inti;
//InitcmdLinetoallNULLSfor(i=0;i<CMD_LINE_LEN;i++){cmdLine[i]='';}printPrompt(NULL, NULL);fgets(cmdLine, CMD_LINE_LEN, stdin);for(i=CMD_LINE_LEN-1;i>=0;i--){if(cmdLine[i]=='\n'){cmdLine[i]='';break;}}returncmdLine;}voidprintPrompt(char*prefix, char*suffix){if(prefix!=NULL){write(fileno(stdout), prefix, strlen(prefix));}if(_prompt!=NULL){write(fileno(stdout), _prompt, strlen(_prompt));}else{write(fileno(stdout), DEFAULT_PROMPT, strlen(DEFAULT_PROMPT));}if(suffix!=NULL){write(fileno(stdout), suffix, strlen(suffix));}fflush(stdout);}
//=================================================================>
//shui.h/*
Author: Robert C. Ilardi
Date: 11/7/2004
Description: Shell Command Line User Interface Header
*/#ifndef PASH_SHUI_H#define PASH_SHUI_H#include <stdio.h>#include <stdlib.h>staticconstintCMD_LINE_LEN=2048;staticconstchar*DEFAULT_PROMPT="PASH> ";voidsetPrompt(char*prompt);char*getCmdLine();voidprintPrompt(char*prefix, char*suffix);#endif
//=================================================================>
//sighandlers.c/*
Author: Robert C. Ilardi
Date: 11/5/2004
Description: Signal Handlers Implementation
*/#include "sighandlers.h"voidinstallSignalHandlers(){signal(SIGINT, sigIntHandler);}voidsigIntHandler(intsig){if(pashDebugMode()){printf("\nSIGNAL(%d) : I Got YOU Baby...\n", sig);}if(sig==SIGINT){controlPrintPrompt(NULL, NULL);}}
//=================================================================>
//sighandlers.h/*
Author: Robert C. Ilardi
Date: 11/5/2004
Description: Signal Handlers Header
*/#ifndef PASH_SIGHANDLERS_H#define PASH_SIGHANDLERS_H#include <signal.h>#include <unistd.h>#include <stdio.h>#include "control.h"voidinstallSignalHandlers();voidsigIntHandler(int);#endif
//=================================================================>
//bool.h/*
Author: Robert C. Ilardi
Date: 10/27/2004
Description: This header file defines the type bool.
*/#ifndef BOOL_H#define BOOL_H #ifndef __cplusplus #ifdef CURSES_LOC #include CURSES_LOC #else #ifndef bool #define bool int #endif #endif #ifndef true #define true 1 #define false 0 #endif #endif#endif
//=================================================================>
//builtin.c/*
Author: Robert C. Ilardi
Date: 11/15/2004
Description: Shell Built In Commands Implementation
*/#include "builtin.h"#include "pash.h"constintBUILT_IN_CMD_CNT=4;constchar*BUILT_IN_CMDS[]={"EXIT", "CD", "DEBUGME", "VER"};boolbuiltInSupport(structCmdLine*cmdLine){inti;boolsupported=false;for(i=0;!supported&&i<BUILT_IN_CMD_CNT;i++){supported=(strcasecmp(cmdLine->command, BUILT_IN_CMDS[i])==0);}returnsupported;}boolbuiltInExecute(structCmdLine*cmdLine){boolsuccess=false;char*param1;booltmpB;if(strcasecmp(cmdLine->command, "EXIT")==0){
//TheShellExitCommandexit(0);}elseif(strcasecmp(cmdLine->command, "CD")==0){if(listSize(cmdLine->parameters)>0){param1=(char*)cmdLine->parameters->head->item;chdir(param1);success=true;}else{fprintf(stderr, "Cannot Change Directory to NOTHING! CD Syntax: cd [DIR]\n");}}elseif(strcasecmp(cmdLine->command, "DEBUGME")==0){pashSetDebugMode(!pashDebugMode());if(listSize(cmdLine->parameters)>0){param1=(char*)cmdLine->parameters->head->item;if(strcasecmp(param1, "NOEXEC")==0){setShellNoExec(true);}}printf("Toggle PASH Shell Debug Mode: %s\n", (pashDebugMode() ? "ON":"OFF"));if(!pashDebugMode()){setShellNoExec(false);}success=true;}elseif(strcasecmp(cmdLine->command, "VER")==0){
//TheShellVersionCommandprintf("** %s **\n", PASH_TITLE);printf("Written By: %s\n", PASH_AUTHOR);printf("Copyright (c) %s By: %s\n", PASH_COPYRIGHT_DATE, PASH_COPYRIGHT_HOLDER);printf("Visit %s\n", PASH_URL);printf("Version: %s\n", PASH_VERSION);}else{puts("Invalid PASH Command!");}returnsuccess;}
//=================================================================>
//builtin.h/*
Author: Robert C. Ilardi
Date: 11/15/2004
Description: Built In Shell Commands Header
*/#ifndef PASH_BUILT_IN_H#define PASH_BUILT_IN_H#include <unistd.h>#include <stdlib.h>#include <string.h>#include <stdio.h>#include "bool.h"#include "cmdline.h"#include "linkedlist.h"#include "pash_consts.h"#include "shell.h"boolbuiltInSupport(structCmdLine*);boolbuiltInExecute(structCmdLine*);#endif
//=================================================================>
//clparser.c/*
Author: Robert C. Ilardi
Date: 11/8/2004
Description: Command Line Parser Implementation
*/#include "clparser.h"constintCL_DELIMITER_IGNORE=0;constintCL_DELIMITER_PUSHABLE=1;constchar*CL_DELIMITERS[]={" 2>", ">>", " ", ">", "<", "|", "&", "\t"};constintCL_DELIMITERS_FLAGS[]={1, 1, 0, 1, 1, 1, 1, 0};constintCL_DELIMITER_CNT=8;constchar*CL_TOKEN_AMP="&";constchar*CL_TOKEN_GREATER_THAN=">";constchar*CL_TOKEN_LESS_THAN="<";constchar*CL_TOKEN_OUT_APPENDOR=">>";constchar*CL_TOKEN_PIPE="|";constchar*CL_TOKEN_ERR_REDIRECT="2>";constintCLP_PIPE_DIRECTION_NONE=-1;constintCLP_PIPE_DIRECTION_READ=0;constintCLP_PIPE_DIRECTION_WRITE=1;constintCLP_PIPE_DIRECTION_READ_WRITE=2;constintREDIRECTS=3;staticchar*trim(constchar*);voidpushCmdLine(structStack*stack, char*command, structLinkedList*parameters,
char*operators[], char*files[], boolpipedIn, boolpipeOut, boolbackground){structCmdLine*cmdLine;inti;cmdLine=(structCmdLine*)malloc(sizeof(structCmdLine));cmdLine->parameters=parameters;cmdLine->command=command;cmdLine->backgroundProcess=background;cmdLine->pipedIn=pipedIn;cmdLine->pipeOut=pipeOut;cmdLine->inFile=NULL;cmdLine->outFile=NULL;cmdLine->errFile=NULL;for(i=0;i<REDIRECTS;i++){if(operators[i]!=NULL&&files[i]!=NULL){if(strcmp(operators[i], CL_TOKEN_GREATER_THAN)==0&&!pipeOut){cmdLine->outFile=files[i];cmdLine->appendOut=false;}elseif(strcmp(operators[i], CL_TOKEN_LESS_THAN)==0&&!pipedIn){cmdLine->inFile=files[i];}elseif(strcmp(operators[i], CL_TOKEN_ERR_REDIRECT)==0){cmdLine->errFile=files[i];}elseif(strcmp(operators[i], CL_TOKEN_OUT_APPENDOR)==0&&!pipeOut){cmdLine->outFile=files[i];cmdLine->appendOut=true;}}}stackPush(stack, cmdLine);}boolisDelimiter(char*s){booldelimiter=false;inti;for(i=0;i<CL_DELIMITER_CNT;i++){if(strcmp(s, trim(CL_DELIMITERS[i]))==0){delimiter=true;break;}}returndelimiter;}structStack*parseCmdLine(constchar*constclStr){structCmdLine*cmdLine;structQueue*tokens;char*token, *nextToken, *command;char**operators, **files;boolbackground, pushed, pipedIn, pipeOut;structStack*commandStack;inti;structLinkedList*parameters;tokens=tokenize(clStr);commandStack=stackCreate();pipedIn=false;pipeOut=false;while(!queueIsEmpty(tokens)){
//GetCommandpushed=false;command=(char*)queueGetFront(tokens);
//ParseParametersparameters=listCreate();if(!queueIsEmpty(tokens)){while(!queueIsEmpty(tokens)){token=(char*)queuePeek(tokens);if(!isDelimiter(token)){listAppend(parameters, token);queueGetFront(tokens);}else{break;}}}
//CheckforRedirectsoperators=(char**)malloc(sizeof(char*)*REDIRECTS);files=(char**)malloc(sizeof(char*)*REDIRECTS);for(i=0;i<REDIRECTS;i++){operators[i]=NULL;files[i]=NULL;}if(!queueIsEmpty(tokens)){for(i=0;i<REDIRECTS&&!queueIsEmpty(tokens);i++){token=(char*)queuePeek(tokens);if(strcmp(token, CL_TOKEN_GREATER_THAN)==0||strcmp(token, CL_TOKEN_LESS_THAN)==0||strcmp(token, CL_TOKEN_ERR_REDIRECT)==0||strcmp(token, CL_TOKEN_OUT_APPENDOR)==0){operators[i]=token;queueGetFront(tokens);token=(char*)queueGetFront(tokens);files[i]=token;}else{break;}}}
//Checkforbackgroundprocessorpipebackground=false;pipeOut=false;if(!queueIsEmpty(tokens)){token=(char*)queuePeek(tokens);if(strcmp(token, CL_TOKEN_AMP)==0){queueGetFront(tokens);background=true;}elseif(strcmp(token, CL_TOKEN_PIPE)==0){queueGetFront(tokens);pipeOut=true;}}
//AddCommandtoStackofCommandspushCmdLine(commandStack, command, parameters, operators, files, pipedIn, pipeOut, background);pushed=true;pipedIn=pipeOut;if(background||!pipeOut){break; //Terminatedbecauseinbackgroundorsyntaxerror}}if(!pushed){free(operators);free(files);}queueDestroy(tokens, false);returncommandStack;}staticchar*trim(constchar*s){structStringBuffer*sb=strBufCreate();char*tStr=NULL;inti;for(i=0;i<strlen(s);i++){if(s[i]!=' '&&s[i]!='\t'){strBufAppendChar(sb, s[i]);}}tStr=strBufToString(sb);strBufDestroy(sb);returntStr;}boolcheckDelimiter(int*index, constchar*constcmdLine,
structStringBuffer*sb, structQueue*tokens){booldelimiter=false;inti, j, forwardLen=0;char*tmp, *s, *delTmp;
//Loopthroughdelimiterscheckifoneisthenexttokeninthecmdlinefor(i=0;i<CL_DELIMITER_CNT;i++){
//Dowehaveenoughcharsinthecmdline
//thatisifpossibletomatchthei'thdelimiter?
if((strlen(cmdLine)-(*index))>=strlen(CL_DELIMITERS[i])){
//extractthesamenumberofchar'sfrom
//thecmdlineasthelengthofthedelimitertmp=(char*)malloc(strlen(CL_DELIMITERS[i])+1);for(j=0;j<strlen(CL_DELIMITERS[i]);j++){tmp[j]=cmdLine[j+(*index)];}tmp[j]=''; //terminatewithnull
//Aretheyequal?
if(strcmp(tmp, CL_DELIMITERS[i])==0){if(strBufLength(sb)>0){s=strBufToString(sb);strBufClear(sb);queueInsert(tokens, s);}delimiter=true;forwardLen=strlen(CL_DELIMITERS[i])-1;if(CL_DELIMITERS_FLAGS[i]==CL_DELIMITER_PUSHABLE){delTmp=tmp;tmp=trim(tmp);free(delTmp);queueInsert(tokens, tmp);}break;}else{free(tmp);}}}*index+=forwardLen;returndelimiter;}structQueue*tokenize(constchar*constcmdLine){structQueue*tokens=queueCreate();structStringBuffer*sb=strBufCreate();char*s;inti;boolinQuotes=false, delimiter;for(i=0;i<strlen(cmdLine);i++){delimiter=false;if(cmdLine[i]=='\"'||cmdLine[i]=='\''){inQuotes=!inQuotes;}elseif(!inQuotes){delimiter=checkDelimiter(&i, cmdLine, sb, tokens);if(!delimiter){
//Non-DelimiterCharacterstrBufAppendChar(sb, cmdLine[i]);}} //End!inQuotesCheckelse{
//inQuotesstrBufAppendChar(sb, cmdLine[i]);}}if(strBufLength(sb)>0){s=strBufToString(sb);strBufClear(sb);queueInsert(tokens, s);}strBufDestroy(sb);returntokens;}
//=================================================================>
//clparser.h/*
Author: Robert C. Ilardi
Date: 11/8/2004
Description: Command Line Parser Header
*/#ifndef PASH_CLPARSER_H#define PASH_CLPARSER_H#include <stdlib.h>#include <string.h>#include "stack.h"#include "strbuffer.h"#include "bool.h"#include "queue.h"#include "cmdline.h"structStack*parseCmdLine(constchar*constclStr);structQueue*tokenize(constchar*consts);#endif
//=================================================================>
//cmdline.h/*
Author: Robert C. Ilardi
Date: 11/8/2004
Description: Command Line Structure Declaration
*/#ifndef PASH_CMDLINE_H#define PASH_CMDLINE_H#include "bool.h"#include "linkedlist.h"structCmdLine{char*command;structLinkedList*parameters;char*outFile;char*errFile;char*inFile;boolappendOut;boolbackgroundProcess;boolpipedIn;boolpipeOut;};#endif
//=================================================================>
//control.c/*
Author: Robert C. Ilardi
Date: 11/7/2004
Description: Process Control Implementation
*/#include "control.h"staticchar*(*_uiGetFunctPtr)(void);staticvoid(*_uiPrompterFunctPtr)(char*, char*);voidinstallUserInterfaceGet(char*(*uiFunctPtr)(void)){_uiGetFunctPtr=uiFunctPtr;}voidinstallUserInterfacePrompter(void(*uiFunctPtr)(char*, char*)){_uiPrompterFunctPtr=uiFunctPtr;}voidcontrolPrintPrompt(char*prefix, char*suffix){_uiPrompterFunctPtr(prefix, suffix);}intrunShell(){char*cmdLine;structStack*cmdStack;for(;;) //LoopForever;WelluntilShellfinds"exit"{
//GetandParseCmdLinecmdLine=_uiGetFunctPtr();if(strlen(cmdLine)==0){continue;}if(pashDebugMode()){printf("Cmd Line = \"%s\"\n", cmdLine);printf("Cmd Line Len = %d\n", strlen(cmdLine));}cmdStack=parseCmdLine(cmdLine);
//EvaulateCommandStackandExecuteexecuteCmdStack(cmdStack);
//FreeMemoryfree(cmdLine);stackDestroy(cmdStack, false); //Itemsinthestackarefree'edbyexecuteCmdStack}return0;}
//=================================================================>
//control.h/*
Author: Robert C. Ilardi
Date: 11/7/2004
Description: Process Control Header
*/#ifndef PASH_CONTROL_H#define PASH_CONTROL_H#include <stdio.h>#include <stdlib.h>#include "stack.h"#include "clparser.h"#include "shell.h"voidinstallUserInterfaceGet(char*(*uiFunctPtr)(void));voidintallUserInterfacePrompter(void*(*uiFunctPtr)(char*, char*));intrunShell();voidprintPrompt();#endif
//=================================================================>
//debugMod.c/*
Author: Robert C. Ilardi
Date: 11/5/2004
Description: Debug Utility Implementation
*/#include "debugMod.h"staticbool_pashDebugMode;voidpashSetDebugMode(booldm){_pashDebugMode=dm;}boolpashDebugMode(){return_pashDebugMode;}
//=================================================================>
//debugMod.h/*
Author: Robert C. Ilardi
Date: 11/5/2004
Description: Debug Utility Header
*/#ifndef PASH_DEBUG_MOD_H#define PASH_DEBUG_MOD_H#include "bool.h"voidpashSetDebugMode(bool);boolpashDebugMode();#endif
//=================================================================>
//linkedlist.c/*
Author: Robert C. Ilardi
Date: 10/29/2004
Description: Doubly Linked List Implementation
*/#include "linkedlist.h"structLinkedList*listCreate(){structLinkedList*linkedList=(structLinkedList*)malloc(sizeof(structLinkedList));linkedList->head=NULL;linkedList->tail=NULL;returnlinkedList;}structListNode*listGetHead(structLinkedList*linkedList){returnlinkedList->head;}structListNode*listGetTail(structLinkedList*linkedList){returnlinkedList->tail;}voidlistInsert(structLinkedList*linkedList, void*item){structListNode*node=(structListNode*)malloc(sizeof(structListNode));node->item=item;node->next=NULL;node->previous=NULL;if(linkedList->head==NULL){linkedList->head=node;linkedList->tail=node;}else{node->next=linkedList->head;linkedList->head->previous=node;linkedList->head=node;}}voidlistAppend(structLinkedList*linkedList, void*item){structListNode*node=(structListNode*)malloc(sizeof(structListNode));node->item=item;node->next=NULL;node->previous=NULL;if(linkedList->head==NULL){linkedList->head=node;linkedList->tail=node;}else{node->previous=linkedList->tail;linkedList->tail->next=node;linkedList->tail=node;}}voidlistClear(structLinkedList*linkedList, booldeleteItems){while(linkedList->head!=NULL){if(deleteItems){free(linkedList->head->item);}free(linkedList->head);linkedList->head=linkedList->head->next;}linkedList->head=NULL;linkedList->tail=NULL;}voidlistRemove(structLinkedList*linkedList, structListNode*node, booldeleteNode, booldeleteItem){if(node!=NULL){
//RemoveNODEfromtheList!if(node->previous!=NULL){node->previous->next=node->next;}else{linkedList->head=node->next;}if(node->next!=NULL){node->next->previous=node->previous;}else{linkedList->tail=node->previous;}
//DeleteItem?
if(deleteItem){free(node->item);}
//DeleteNode?
if(deleteNode){free(node);}}}voidlistDestroy(structLinkedList*linkedList, booldeleteItems){listClear(linkedList, deleteItems);free(linkedList);}intlistSize(structLinkedList*linkedList){intsize=0;structListNode*node;node=linkedList->head;while(node!=NULL){size++;node=node->next;}returnsize;}
//=================================================================>
//linkedlist.h/*
Author: Robert C. Ilardi
Date: 10/29/2004
Description: Doubly Linked List Declaration
*/#ifndef PASH_LINKEDLIST_H#define PASH_LINKEDLIST_H#include <stdlib.h>#include "bool.h"structListNode{void*item;structListNode*next;structListNode*previous;};structLinkedList{structListNode*head;structListNode*tail;};structLinkedList*listCreate();structListNode*listGetHead(structLinkedList*);structListNode*listGetTail(structLinkedList*);voidlistInsert(structLinkedList*, void*);voidlistAppend(structLinkedList*, void*);voidlistClear(structLinkedList*, bool);voidlistRemove(structLinkedList*linkedList, structListNode*, bool, bool);voidlistDestroy(structLinkedList*, bool);intlistSize(structLinkedList*);#endif
//=================================================================>
//queue.c/*
Author: Robert C. Ilardi
Date: 10/29/2004
Description: Queue Implementation using Doubly Linked List
*/#include "queue.h"structQueue*queueCreate(){structQueue*queue=(structQueue*)malloc(sizeof(structQueue));queue->list=listCreate();returnqueue;}voidqueueDestroy(structQueue*queue, booldeleteItems){listDestroy(queue->list, deleteItems);free(queue);}voidqueueInsert(structQueue*queue, void*item){listAppend(queue->list, item);}void*queueGetFront(structQueue*queue){void*item=queue->list->head->item;listRemove(queue->list, queue->list->head, true, false);returnitem;}void*queuePeek(structQueue*queue){returnqueue->list->head->item;}intqueueSize(structQueue*queue){returnlistSize(queue->list);}boolqueueIsEmpty(structQueue*queue){returnqueue->list->head==NULL;}
//=================================================================>
//queue.h/*
Author: Robert C. Ilardi
Date: 10/29/2004
Description: Queue declaration
*/#ifndef PASH_QUEUE_H#define PASH_QUEUE_H#include "linkedlist.h"structQueue{structLinkedList*list;};structQueue*queueCreate();voidqueueDestroy(structQueue*, bool);voidqueueInsert(structQueue*, void*);void*queueGetFront(structQueue*);void*queuePeek(structQueue*);intqueueSize(structQueue*);boolqueueIsEmpty(structQueue*);#endif
//=================================================================>
//stack.c/*
Author: Robert C. Ilardi
Date: 10/29/2004
Description: Stack Implementation using Doubly Linked List
*/#include "stack.h"structStack*stackCreate(){structStack*stack=(structStack*)malloc(sizeof(structStack));stack->list=listCreate();returnstack;}voidstackDestroy(structStack*stack, booldeleteItems){listDestroy(stack->list, deleteItems);free(stack);}voidstackPush(structStack*stack, void*item){listInsert(stack->list, item);}void*stackPop(structStack*stack){void*item=stack->list->head->item;listRemove(stack->list, stack->list->head, true, false);returnitem;}void*stackPeek(structStack*stack){void*item=stack->list->head->item;returnitem;}boolstackIsEmpty(structStack*stack){returnstack->list->head==NULL;}voidstackClear(structStack*stack, booldeleteItems){listClear(stack->list, deleteItems);}intstackSize(structStack*stack){returnlistSize(stack->list);}
//=================================================================>
//stack.h/*
Author: Robert C. Ilardi
Date: 10/29/2004
Description: Stack declaration
*/#ifndef PASH_STACK_H#define PASH_STACK_H#include "linkedlist.h"structStack{structLinkedList*list;};structStack*stackCreate();voidstackDestroy(structStack*, bool);voidstackPush(structStack*, void*);void*stackPop(structStack*);void*stackPeek(structStack*);boolstackIsEmpty(structStack*);voidstackClear(structStack*, bool);intstackSize(structStack*);#endif
//=================================================================>
//strbuffer.c/*
Author: Robert C. Ilardi
Date: 10/29/2004
Description: String Buffer Implementation
*/#include "strbuffer.h"constintSB_BUFFER_LEN=10;structStringBuffer*strBufCreate(){structStringBuffer*sb=(structStringBuffer*)malloc(sizeof(structStringBuffer));sb->list=listCreate();sb->pos=0;sb->buffer=(char*)malloc(sizeof(char)*SB_BUFFER_LEN+1);sb->buffer[0]='';returnsb;}voidstrBufDestroy(structStringBuffer*sb){listDestroy(sb->list, true);sb->pos=0;free(sb->buffer);free(sb);}voidstrBufClear(structStringBuffer*sb){listClear(sb->list, true);sb->pos=0;}voidstrBufAppendChar(structStringBuffer*sb, charc){if(sb->pos<SB_BUFFER_LEN){sb->buffer[sb->pos]=c;sb->pos++;sb->buffer[sb->pos]='';}else{listAppend(sb->list, sb->buffer);sb->buffer=(char*)malloc(sizeof(char)*SB_BUFFER_LEN+1);sb->pos=1;sb->buffer[0]=c;sb->buffer[1]='';}}voidstrBufAppendStr(structStringBuffer*sb, char*s){inti;for(i=0;i<strlen(s);i++){if(sb->pos<SB_BUFFER_LEN){sb->buffer[sb->pos]=s[i];sb->pos++;sb->buffer[sb->pos]='';}else{listAppend(sb->list, sb->buffer);sb->buffer=(char*)malloc(sizeof(char)*SB_BUFFER_LEN+1);sb->pos=1;sb->buffer[0]=s[i];sb->buffer[1]='';}}}char*strBufToString(structStringBuffer*sb){char*str=NULL;intlen=0;structListNode*node;node=sb->list->head;while(node!=NULL){len+=SB_BUFFER_LEN;node=node->next;}len+=sb->pos+1;if(len>0){str=(char*)malloc(sizeof(char)*len);str[0]='';node=sb->list->head;while(node!=NULL){strcat(str, (char*)node->item);node=node->next;}strcat(str, sb->buffer);}returnstr;}intstrBufLength(structStringBuffer*sb){intlen=0;len+=listSize(sb->list)*SB_BUFFER_LEN;len+=sb->pos;returnlen;}
//=================================================================>
//strbuffer.h/*
Author: Robert C. Ilardi
Date: 10/28/2004
Description: This file is the header file for the String Buffer.
*/#ifndef PASH_STRBUFFER_H#define PASH_STRBUFFER_H#include <stdlib.h>#include <string.h>#include "linkedlist.h"structStringBuffer{structLinkedList*list;intpos;char*buffer;};structStringBuffer*strBufCreate();voidstrBufDestroy(structStringBuffer*);voidstrBufClear(structStringBuffer*);voidstrBufAppendChar(structStringBuffer*, char);voidstrBufAppendStr(structStringBuffer*, char*);char*strBufToString(structStringBuffer*);intstrBufLength(structStringBuffer*);#endif
//=================================================================>
While on my latest trip to London, I was posed the question: “What does it take the cultivate good System Architects within you organization?”
As I’m currently sitting in the Virgin Atlantic Clubhouse waiting for my flight back to the states, I don’t have the time to answer this question in full. And actually, I’m posting this more for me than for my readers. I want to think about the answer to this question and what better way than to force myself into a two part blog article.
Most IT organizations throw around the word “Architect” all to easily when we title someone.
The truth is hiring or growing a real system architect is harder than most people think.
I mentioned to someone asking me this question that when giving year end reviews to my most senior developers I always mention the 5 attributes that make up a strong architect, and a all around solid developer who will have the potential to grow into an Architect for my organization.
These 5 elements relate to how developers and architects MUST think when they design and construct systems. Any system we build to be truly enterprise class must be: Stable, Scalable, Flexible, Extensible, and Easily Maintainable. The last thing we want is to design an implement a system that only the original designers or developers can maintain.
If your staff can design and implement system that meet these 5 requirements, than I feel those people are worth pushing towards an architect role, where they can start getting their feet wet with design larger components and eventually entire systems on their own for you.
I want to explore this question further in a future post, where we discuss how to test and allow senior developers to prove that they can represent you as a system owner in architectural discussions not only as a leader in your group, but also in sessions with other peer groups, so that your organization appears competent to both clients of your services and providers of services.
Just Another Stream of Random Bits…
– Robert C. Ilardi
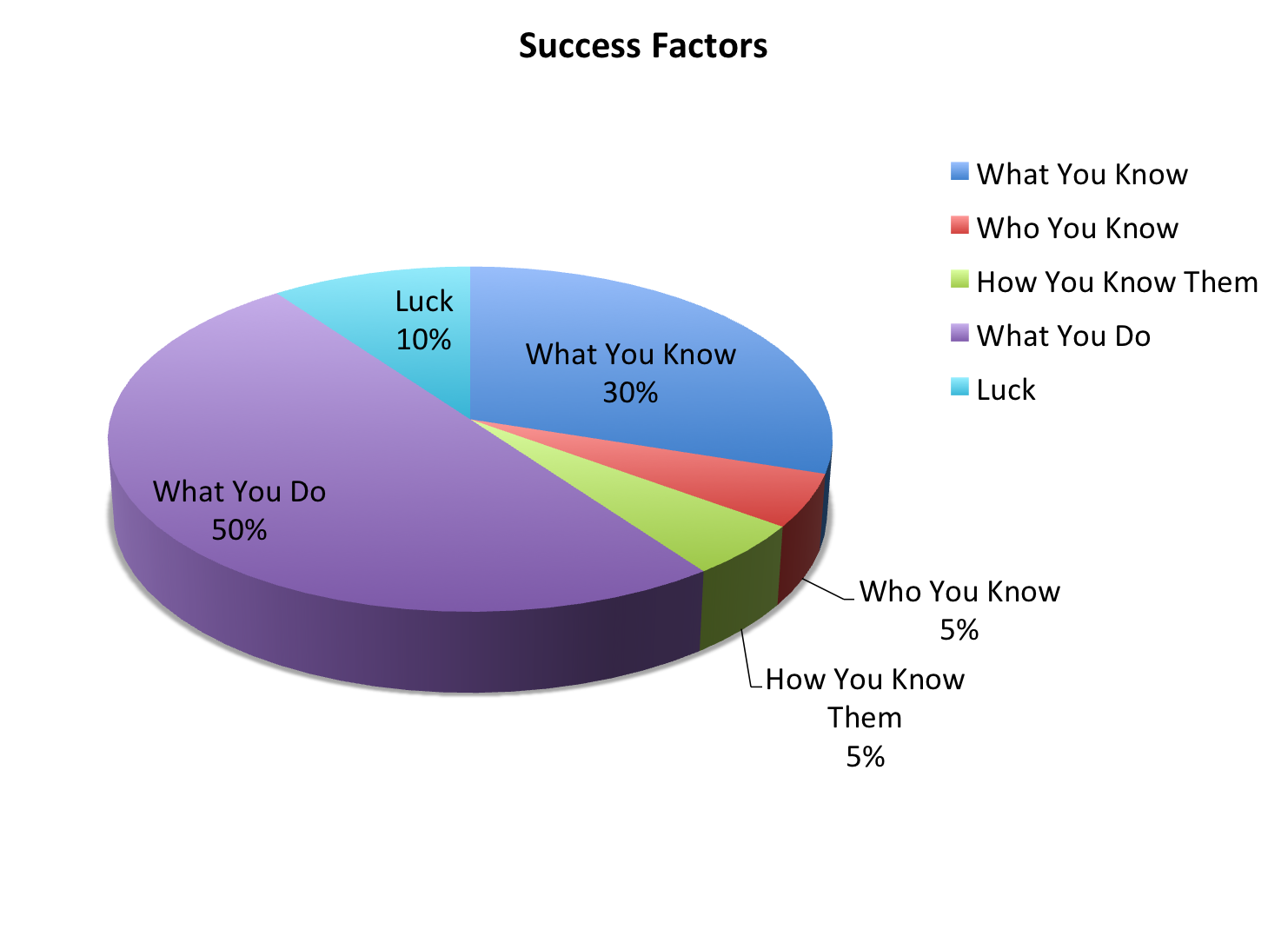
This month I finished up my 2012 Year-End Reviews for my Employees. Looking back on the process and my individual conversations with my employees, I came up with a “Recipe for Success” Pie Chart. I’m thinking about using it for my employee’s Mid-Year Reviews for 2013, but I figured I share it on my blog first; as I think this could be of great help to answering one of the most difficult set of questions faced by Managers or Employers from their Employees; that is the questions around “Advancement”.
Specifically I plan on using this when an Employee has questions around Advancement either for Promotions or Compensation. Also I want to use this for more junior employees that I feel have the potential for Advancement.
When you see the Pie Chart below in this post, please don’t pay too much attention to the actual percentage values, they are there simply to give the slices of the pie an appropriate portion of what I personally consider the important factors to success. The actual values should not be considered exact in any way, but just as the actual recipe for success is something that is more of an Art than a Science, and therefore even the title of this post is technically incorrect, I think seeing the portion of the pie and how they relate to each other in terms of their size is more accurate of a representation than the actual numbers. I know this might seem confusing at first, but I assure you once you see the graph it will make more sense to you.
So what are the Factors of Success? From my personal experience, and yes these factors may vary slightly from person to person if you ask a successful person what made them successful, but I feel in some underlining way, most if not all of these factors have played a role in the success of most people.
Recipe of Success (The Ingredients or Factors):
Note: Lowest Order of Importance is most important; 1 being the most important. There is a 0, however that’s really undefined; you’ll see what I mean when you read this part.
What You Know
Order of Importance: 2
This factor represents your Skills, Knowledge, Education, and Experience.
As an Educator I know pointed out, I should have/could have listed “What you Learned” as a separate slice of the pie. And he’s right. Actually I wanted to write more about this section before I published it, but hit the publish button instead of save by mistake.
Education both from established institutions such as Schools as well as Knowledge gained from personal and professional projects is invaluable.
Sometimes I value Knowledge gained from projects both personal and professional over official classroom based education and textbooks, especially in the realm of technology and specifically software development. See my blog post on Education verses Experience.
So I have to agree with my friend Donald that “What You Learned” should have it’s own slice of the pie, but I’m being lazy here, if it wasn’t so much work on a Saturday afternoon to edit that damn Pie Chart in Excel and PowerPoint and save it as an image again, I would do it!
Who You Know
Order of Importance: 4
Everyone will tell you knowing the right people is your ticket to success, in school, jobs, and otherwise. However I feel the next attribute of my Success Pie is more important. Knowing the Right People of course is important, but just the fact that you “know” someone is unimportant. I know people that know CEOs of companies, but those same CEOs wouldn’t give them jobs, because they either lack too many of the other Factors of Success or they are more of an Acquaintance and really don’t know them, or in general just wouldn’t put their name on the line for that person.
In my experience, people throw the word “Friend” around too casually. Acquaintance is more appropriate for most of the relationships in our lives; again in my opinion.
However you must first know someone before they get to know you and you get to know them. That’s where the next ingredient comes into play.
How You Know Them
Order of Importance: 3
This factor is really the second half of “Who You Know”. As I mostly explained already, simply the fact that you “know” someone is insignificant. It is how you know them or rather really how they know you, that’s important.
This includes the depth of information on the professional level, although sometimes for some people even some personal facts are important, but remember TMI (Too Much Info) when getting into the realm of personal facts.
A person in a position of power that you want to leverage to help you succeed needs to know that they can trust you. That you will not hurt their own reputation, and that if they give you a task that you will succeed and make both you and them look good. They need to know that you will be a good representative for them.
These reasons and others are why “How You Know Them” is more important than “Who You Know.” But again it’s a complimentary ingredient to “Who You Know.” But please remember there’s a big difference and simply knowing someone doesn’t count for much by itself.
Some people will disagree here, but they do not understand what I mean, if they are “close friends”, etc, that means they trust you, which again relates to “How You Know Them” or “How They Know You.”…
What You Do (Or “Deliver”)
Order of Importance: 1
This is possibly the most important factor of success.
Everything up until this point helps you to Deliver. And what you Do or Deliver is the most important thing for your successes in life.
You have to Walk the Walk, not just Talk the Talk.
When you list experience on a resume, you better make sure that you actually Delivered what your experience says, because good interviewers can see right through the people who never delivered, but were still “part of a project.”
Your Skills, Education, Past Experience both Professionally and Personally, Connections, all add up to this moment. This is the moment you take center stage and show to the world you can actually do it; make it happen.
What you Deliver is why you get promoted, get more job offers when you aren’t even looking, get the big bonus or that raise, or grow your team and responsibilities.
This is when you earn that Pay Check, make it count!
Luck (See Below for expansion on this, too many sub-factors…)
Order of Importance: 0 (Why ZERO? Because I think it’s hard to quantify how important Luck really is, and will vary person by person.)
What is Luck? Luck is:
Being in the right place at the right time.
Saying the right things.
Knowing the right people.
Doing the right things.
Succeeding at a task instead of failing against the odds.
Making the right choices in general.
Getting the chance to work on the right projects.
Getting hired for the right job that will give you the opportunities to gain experience, exposure, etc.
Graduating at the right time.
Working for the right group or department or company.
Going to the right schools.
Participating in the right extracurricular activities.
Being seen when it counts.
The list can go on and on. This is why it’s considered ZERO on my list of ingredients in terms of Order of Importance. The definition of Luck itself is infinite and cannot really be determined. We can list components of what is luck, but really you only need some of them to help you be successful, not all of them.
I hear all to often people saying I just wasn’t lucky. Although there may be some truth to this because you might be equally as good as someone else or maybe even better but maybe you missed some of the other attributes of what makes a person successful, or perhaps it really is a missing component that I listed under luck, for example, being at the right place at the right time.
I am a Capitalist and I believe in the principals of Capitalism. And my Recipe for Success “Pie” applies only to a Capitalistic Society. I even wear a T-Shirt that says “Capitalist” on the front of it in a baseball styled font. So I don’t believe that we have to live in a Socialist vision of a fair society. Instead I believe to our Government should support Capitalism and Freedom and simply allow for the chance that someone, anyone, no matter where they come from or who they are, can become successful, but that does not mean that any specific individual will be successful.
I don’t want to make this post get too political so I’ll stop it right here. But let’s face it, Luck does play some roll in a Capitalistic Society, and that’s ok…
Any how, it’s time for Pie…
I’m interested if any other managers feel points from this post or my Pie Chart are useful for their own Employee Reviews when an employee asks about advancement. Please feel free to contact me on my contact page or leave some comments. Also I would like to hear any general comments from anyone if they agree or disagree with any of my points, or feel I should even consider adding additional “Ingredients” to my Success Pie.
Just Another Stream of Random Bits…
– Robert C. Ilardi
My favorite agile software development method, is Pair Programming. It is a technique where two programmers will work together at a single computer, working on the same project or component. One is known as the Driver, the person who is actually writing the code, and the other is the Observer (of Navigator if we want to use the Car Driving or Piloting terms) who is looking for bugs, looking for solution, and just all around throwing out ideas to the driver.
In my experience using this technique, the Pair of Programmers swap between Driver and Observer throughout the development of the component they are working on.
The process was probably created organically verses someone actually just thinking up a new SDLC Method, two programmers who were probably friendly around the office decided to work on a problem together and sat in the same cube or otherwise next two each other.
This has been my experience as well. I did not know I was participating in a truly established Software Development Technique, until way later in my career and I started reading more about SDLC models and the like.
A coworker who I was working with on a project and I started to become friendly, and at the time I was a junior developer, especially in the realm of Large Scale Web Applications, and he was hired as a Senior Web Applications Developer, actually the first on our small team. I had some personally experience with creating CGI scripts and it’s one of my God Given Gifts to be able to extrapolate things (especially computer things) very quickly, given very little information, and I had him help me setup a Servlet container server on my local workstation, so I could help develop the Servlets and JSP pages, which at the time I had no experience with. He naturally took the lead, but quickly saw, that although I lacked the experience with Web App development, I did have very solid programming and database skills, so we would start passing code back and forth through shared drives, emailing ZIPs, etc, and then we released why should we waste time doing that when we sat just one row of cubes away from each other, so we started sitting together at his cube (because his row was more empty than mine, and we could talk louder without bothering other developers around us).
He might have known the term Pair Programming without my knowledge, because he often used the Driver and Navigator terms, I knew what he meant by each of them, because he especially in the beginning started saying would you like to Drive, and stand up to switch seats, etc…
I find Pair Programming very effective for training junior developers as well. Currently at the time of writing this blog entry, I have a pair of more Junior Developers working in this type of format right now, and I strategically placed their cubes right next to each other without a partition so they can roll back and forth on their office chairs and switch very easily between Driver and Navigator, it has been working great, and both of them have been coming up to speed on helping to develop larger and larger components more quickly than I first anticipated. The Tech Lead who runs the team I have these two developers reporting to, was quite skeptical at first, but even he has turned around and started giving them larger projects to work on. I very happy with their progress, and although they are both extremely intelligent developers, I attribute the speed at which they have been able to work and deliver within a high stress enterprise level environment, to the Pair Programming model which they have been working in.
No developer can possibly know everything, and having another highly skilled developer watching your back can be invaluable especially when you are under the clock to deliver products quickly and without bugs.
You can read the Wikipedia article on Pair Programming, for the details on it, but honestly it’s a small article, and there’s really nothing to the model, other than you have two programmers that have a good rapport with each other work together at a single workstation (or better yet two workstations right next to each other, so that the Navigator can lookup API docs and other tips in the MAN Pages or the Internet, or other online reference source, quickly, while the Driver continues writing code.), working on the same project or component, and each of them play both the roles of the Driver and the Observer/Navigator. Again the Driver is the person who is writing the code at a given moment, and the Observer/Navigator is the one looking over the Drivers shoulders, looking for bugs on each line of code the Driver is writing (this reduces bugs in real time), and is constantly thinking about the next component or function of the current component, so the Pair can very quickly move on writing the code. The Wikipedia article on this says the Driver is working on the here and now or tactical aspects of the code, writing the lines of code in real time, while the Navigator is reading the lines of code looking for bugs while thinking about the strategic aspect of the code.
I also have found that if you setup a large enough cube or work area or the two developers, so the Navigator could quickly lean over and start typing on the Drivers keyboard while still wearing the Navigator hat to quickly fix a bug, etc, this is extremely helpful and again produces a better quality of code.
Pair Programming needs to be embraced by management of course, because it is easy to mistaken two programmers goofing off or the Navigator not really doing his or her job, but this is a big misconception, the Navigator is playing a very crucial role, in helping to produce quality code with a reduced time to market, and shortened QA/SIT cycles. Also if you as a manager associate a particular persons cube with the person who is the Driver all the time, you are mistaken, the two programmers may simply fine that particular cube move comfortable, or perhaps, the programmer who is physically assigned to that cube has a better workstation or better development tools installed, etc.
As I stated in this article, no single developer can possibly know everything, and an even bigger problem is that sometimes, quite often actually, when working on large scale projects, a developer can easily fall into a rut and have tunnel vision when trying to write a component to solve some problem. This is the programmer’s equivalence of Writers Block. A typical technique for solving this problem is to walk away from your desk, maybe get some fresh air, or to sleep on it, etc. Pair Programming however offers another solution to this problem, because for one thing it takes some weight off your shoulders and with two people looking at the same issue, often, someone will spot a solution that both of them working separately may have never come up with.
I look at it like the two programmers constantly bouncing ideas off of one another. Just like brain teasers gets the creative juices flowing by allowing dark neural pathways to light yup like a Christmas Tree, I believe a small group of individuals with similar skill sets do the same thing because the human brain is quite remarkable, and we are social beings and together just talking to each other (Keep Talking by Pink Floyd quickly comes to mind), seems to have been the key to humans creating an advanced civilization, at least to me. You never know what small seemingly insignificant statement, just a couple of words even, that the Navigator mentions to the Driver, lights up an individual. It’s like when Data from Star Trek – The Next Generation is processing something really intensively, like accessing the Borg Collective, his Positronic Neural Net starts blinking in patterns like crazy! I have seen in countless times when I have participated in Pair Programming. My partner will mention something it might only even be half related to the project we were currently working on, but I’ll scream, “I Got It!” and we talk out the idea together and quickly write out the code before either of us forgets it.
I highly recommend that if your managers approve of the practice, for younger developers to participate in Pair Programming.
And for more Senior Developers, working in Pairs with either another senior developer or even a junior developer, will help open your mind to new ideas when developing your critical components. The phrase “Two Minds Are Better Than One” really rings true here!
Pair Programming falls under the scope of Extreme Programming. Which is another great topic for discussion in another blog entry I’ll have to write…
Just Another Stream of Random Bits…
– Robert C. Ilardi
As a hiring manager, I am often faced with the question of Education verses Experience. This extends beyond hiring experienced candidates, to entry level candidates as well. A usual rule of thumb for experienced hires is that 5 solid years of experience is equivalent to a Masters Degree, assuming that person already has a Bachelors. And I will go further to say, that if the candidate with 5 years experience worked on at least one hard core project that was released and supported in a production environment, that experience is worth much more than a Masters.
Convention of most firms dictates that we only hire candidates from the top schools and the top of their classes. For entry level candidates you will often see firms at Career Fairs and other Campus Recruiting events advertising requirements that state a GPA of 3.5 or above or something similar.
In my experience both the GPA and the school selection limits your ability to find quality candidates.
Specifically for programming and other Information Technology related jobs, we as hiring managers and human resource professionals need to broaden our searches.
A student with a 3.0 GPA which is still pretty good, who has spend their personal time working on programming projects, perhaps posting them on Source Forge or other Open Source directories or collaboration sites is much more worth my time as an interviewer, than a student who spend 100% of the time head deep in the books getting that 3.8 or even a 4.0 GPA.
The fact that the student takes time out of their personal schedule to program for fun or simply to help an open source project along, demonstrates that they are enthusiastic about programming and that they have experience working outside the safety of the classroom setting; which although challenging in it’s own way, the classroom and the programming problems given by the majority of Computer Science programs have known solutions and are achievable. Not all problems in the real world have easy or predictably achievable solutions like they do in the classroom.
I do understand some students of computer science student and research very abstract problems which may not have a solution for many years or even decades, but those are usually very academic problems. Again this blog is about Real World Enterprise Programming, so I don’t cover those cases including in this post.
The majority of programming jobs out there do not involve these very academic problems; we live in a practical world and practical solutions are usually what Enterprise level development demands.
Having stated my case that I obviously value Experience (both professionally and personally) over education, I still believe you need a solid basis of a computer science curriculum to be successful in Enterprise Programming.
From a Enterprise Programming view point, additional course work with Databases and Unix Programming (A Great book for this is: Advanced Unix Programming, this book helped me build my own Unix SHell: The PASH SHell) are also extremely important.
Universities, like my own, NYU Polytechnic usually focus on the theory and no so much on the practical. The professors expect you to sit in the labs, your dorms, your homes, and learn the programming languages inside and out, on your own time. For example, I had a project involving P-Threads in my Operating Systems course, which we were expected to either already know or learn on our own.
And during any of my interviews, I ensure myself or whoever I delegate the Interview Process to, covers Data Structures, Object Oriented Programming and Design, and the other topics I described above. However we can’t just stop at the theory; my interview process involves writing actual code, and tests to see if the candidate can apply the basic topics they learned in school to real world problems faced by developer on the job in the industry for which they are applying.
This just goes to show me that experience wins over education 10 times out of 10. I know my friends and family who work at Universities and other educational institutions are going to hate me for saying this, but it’s true, at least in my business…
This extends to experienced hires as well. I read 100’s of resumes every year and the candidates who demonstrate an interest in programming outside of the workspace, for example, have open source projects which they are a part of, or have their own web site or blog about programming or other Information Technology topics, always have a one up in my mind.
This post is going to eventually lead into an article I’ll write about “How to Interview High Caliber Developers”…
Just Another Stream of Random Bits…
– Robert C. Ilardi